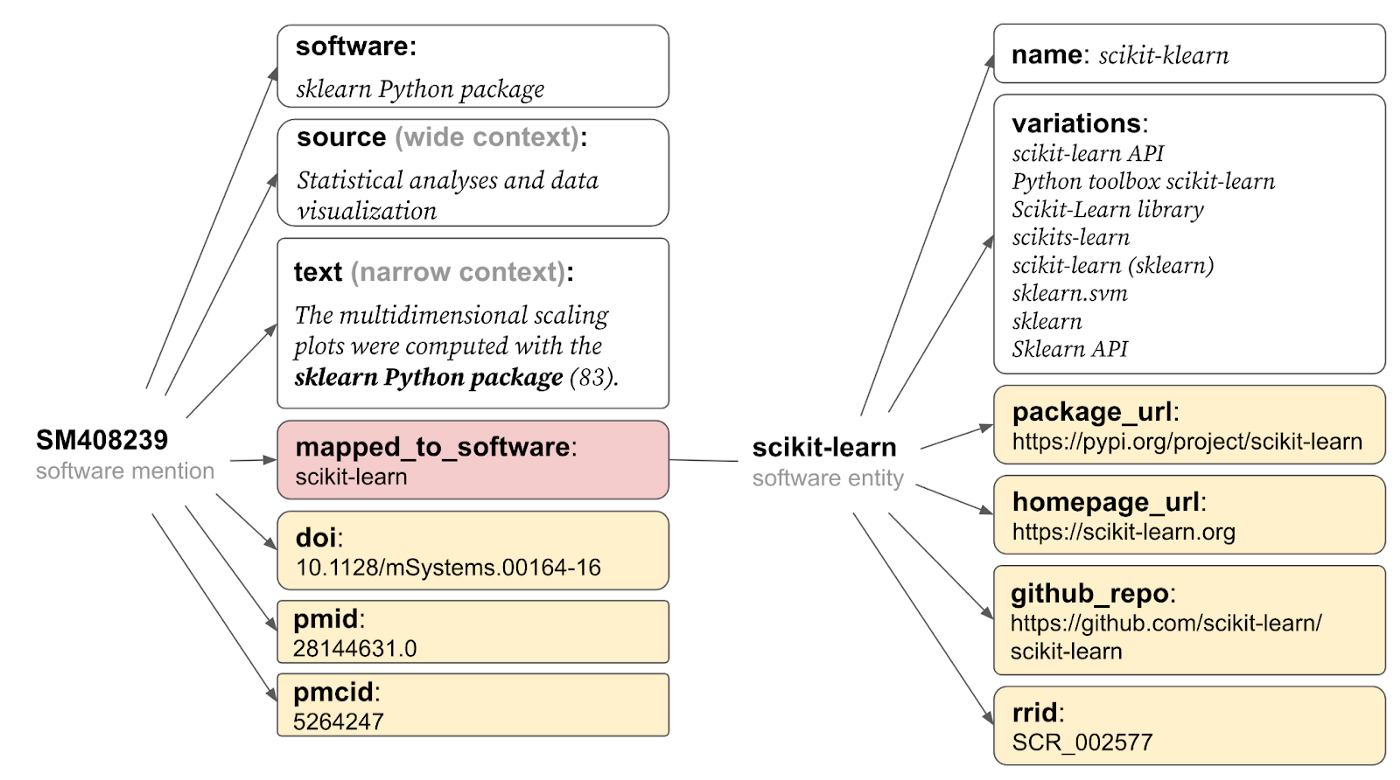
I built a Machine Learning model that extracts mentions of datasets from biomedical research papers. This data will be used for the Open Global Data Citation Corpus. The webinar discusses the significance of building this corpus.
Decription: Wellcome Trust and the Chan Zuckerberg Initiative Partners with DataCite to Build the Open Global Data Citation Corpus
Aggregated references to data across outputs will help the community monitor impact, inform future funding, and improve the dissemination of research
DataCite is pleased to announce that The Wellcome Trust has awarded funds to build the Open Global Data Citation Corpus to dramatically transform the data citation landscape. The corpus will store asserted data citations from a diverse set of sources and can be used by any community stakeholder.
Interested community stakeholders are invited to join the virtual kick-off and participate in a conversation between DataCite, Wellcome Trust, Chan Zuckerberg Initiative, EMBL-EBI, COKI, OpenAIRE, and OpenCitations.
Webinar Link
Presentation Available on Youtube